J. Math. Biol. 64 (2012) p. 403-422
Nicolas Bacaër
Institut de recherche pour le développement, Bondy, France
nicolas.bacaer@ird.fr
Université Cadi Ayyad, Laboratoire de Mathématiques et Dynamique des Populations, Marrakech, Maroc
La figure montrant comment le modèle de Kermack et McKendrick s'ajuste aux données de 1906 pour l'épidémie de peste à Bombay est l'une des figures les plus reproduites dans les livres sur la modélisation mathématique en épidémiologie. Dans cet article, on montre que l'hypothèse de paramètres constants dans ce modèle conduit à des valeurs numériques irréalistes pour ces paramètres. De plus, les rapports publiés à l'époque montrent que des épidémies de peste se produisaient à Bombay avec une saisonnalité remarquable chaque année à partir de 1897 et au moins jusqu'en 1911. Donc l'épidémie de 1906 n'est vraiment pas un bon exemple d'épidémie s'arrêtant parce que le nombre de personnes susceptibles a baissé sous un certain seuil, comme l'ont suggéré Kermack et McKendrick, mais un exemple d'épidémie saisonnière. On présente un modèle saisonnier pour la peste à Bombay et l'on calcule les reproductivités nettes associées aux rats et aux puces. Ce faisant, on étend aux modèles périodiques la notion introduite par Roberts et Heesterbeek.
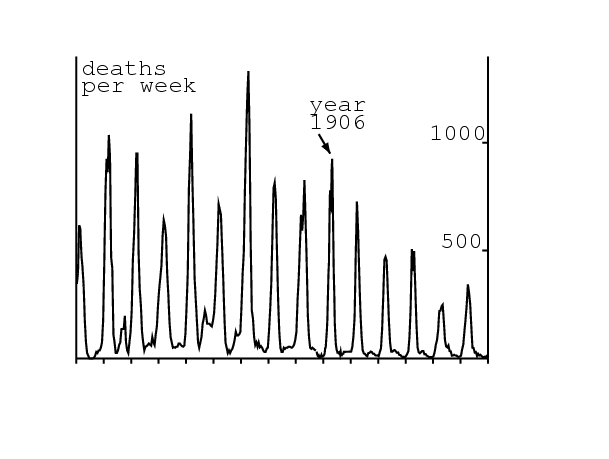
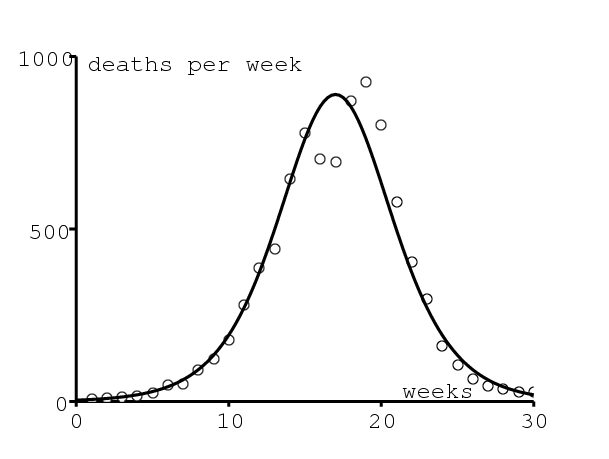
La figure montrant comment le modèle de Kermack et McKendrick (1927 ; 1991) s'ajuste aux données de 1906 pour l'épidémie de peste à Bombay est bien connue des modélisateurs en épidémiologie (figure 1). Elle a été reproduite dans des livres sur l'épidémiologie mathématique (Keeling et Rohani, 2008 ; Waltman, 1974), la biologie mathématique (Banks, 1994 ; Britton, 2003 ; Cavalli-Sforza et Feldman, 1981 ; Edelstein-Keshet, 2005 ; Hastings, 1997 ; Mangel, 2006 ; Murray, 2002 ; Olinick, 1978 ; Shigesada et Kawasaki, 1997), les équations différentielles (Braun, 1993) et l'histoire de la modélisation mathématique (Bacaer, 2011 ; Israel, 1996). Les données, dont Kermack et McKendrick (1927) ne précisent pas l'origine, viennent d'un rapport d'enquête sur la peste en Inde publié en 1907 (Advisory Committee, 1907b, p. 753).
Cependant Kermack et McKendrick n'ont pas obtenu la courbe en cloche de la figure 1 directement à partir de leur modèle original, un système de trois équations différentielles, car celles-ci n'avaient pas de solution explicite. Ils ont utilisé à la place une certaine approximation, pour laquelle ils ont obtenu une solution explicite: le nombre de décès par unité de temps \(dz/dt\) était de la forme \begin{equation}\tag{1} \frac{dz}{dt} \simeq \frac{A}{\cosh^2 (B\, t-\phi )}\; , \end{equation} où les trois paramètres \(A\), \(B\) et \(\phi\,\) dépendent de manière compliquée des paramètres du modèle. L'ajustement aux données donnait \(\,A=890\) par semaine, \(B=\mbox{0,2}\) par semaine et \(\phi=\mbox{3,4}\). Kermack et McKendrick ont aussi mentionné plusieurs hypothèses simplificatrices de leur modèle; par exemple, leur modèle ne tient pas compte explicitement des rats et des puces qui transmettent la peste. Ils ont remarqué que:
« None of these assumptions are strictly fulfilled and consequently the numerical equation can only be a very rough approximation. A close fit is not to be expected, and deductions as to the actual values of the various constants should not be drawn. »
Malgré cette mise en garde, il peut être intéressant d'étudier cela de plus près. En particulier, on peut se demander:
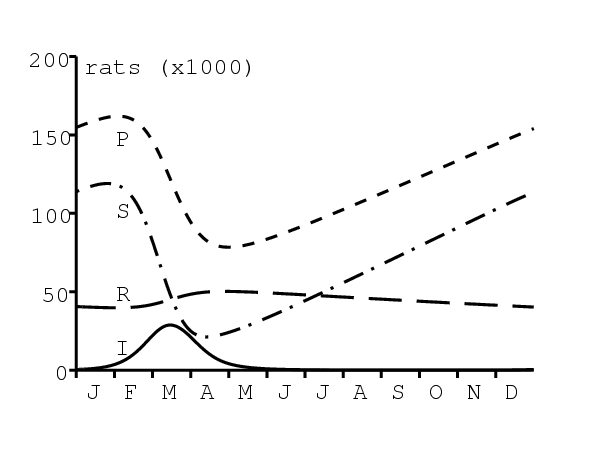
Dans la section 2, on rappelle le contexte historique et les formules obtenues par Kermack et McKendrick. Dans la section 3, on présente les calculs qui permettent de retrouver les valeurs des paramètres à partir de l'ajustement, on les appliquent au cas de la peste à Bombay et l'on explique que les valeurs obtenues sont assez irréalistes. Il faut donc remettre en cause l'hypothèse des valeurs constantes pour les paramètres. La section 4 discute du rôle de la saisonnalité, qui est sûrement responsable du déclin de l'épidémie en 1906, et propose un modèle périodique pour cette épidémie de peste. Le modèle comprend les puces, les rats et les humains comme dans (Keeling et Gilligan, 2000 ; Keeling et Gilligan, 2000 ; Monecke et coll., 2009). Noter cependant que (Monecke et coll., 2009) ne considère que des épidémies d'une année sans tenir compte de la saisonnalité. Un des modèles dans (Keeling et Gilligan, 2000) était saisonnier mais regardait à l'échelle du siècle, de sorte que
« the effects of the seasonal fluctuations are averaged out. »La section 5 présente d'abord une définition de la reproductivité d'un type pour les modèles périodiques. Celle-ci est appliquée au modèle de la section précédente. Ceci étend les travaux de Roberts et Heesterbeek sur les modèles dans un environnement constant (Heesterbeek et Roberts, 2007 ; Roberts et Heesterbeek, 2003 ; Roberts, 2007). La section 6 lie la reproductivité d'un type de notre modèle périodique avec la reproductivité d'un modèle réduit. La dernière section mentionne quelques pistes possibles pour des travaux futurs.
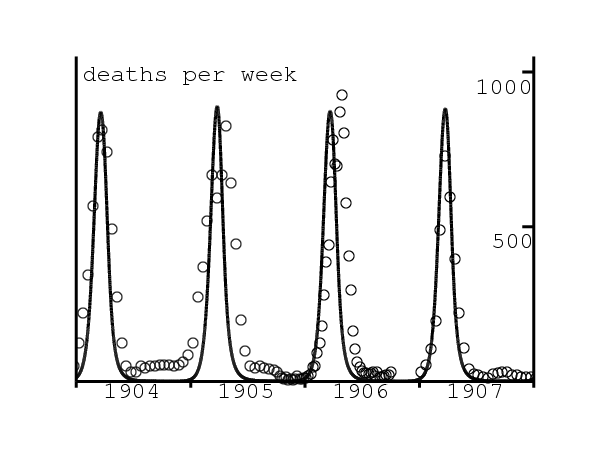
La peste bubonique apparut à Bombay, désormais Mumbai, en août 1896 (Gatacre, 1897). Elle devint endémique en réapparaissant les années suivantes avec un fort caractère saisonnier comme on va le voir dans la section 4. La peste se répandit aussi à travers l'Inde, ce qui causa plus de dix millions de morts entre 1898 et 1918 (Pollitzer, 1954, p. 26). En janvier 1905, le secrétaire d'état aux Indes, la Royal Society et l'institut Lister créèrent un comité consultatif. Sa commission de travail était basée à Bombay. La commission fit de nombreuses expériences de laboratoire et études de terrain pour étudier tous les aspects de la maladie. En conséquence, pas moins de quatre-vingt-quatre « Rapports d'étude sur la peste en Inde », avec des centaines de tableaux, de diagrammes et de cartes, furent publiés entre septembre 1906 et avril 1917 comme numéros spéciaux du \(\text{Journal of Hygiene}\). Ce journal a maintenant été numérisé et qui est accessible gratuitement sur www.ncbi.nlm.nih.gov/pmc/journals/326/. La plupart des informations de notre article viennent de ces rapports.
L'épidémie saisonnière de peste de 1906, qui dura de janvier à juillet 1906, fut la première épidémie que la commission étudia et aussi celle qui reçut la plus grande attention. Mais en réalité elle fut d'une « sévérité modérée ». La commission fut capable d'établir définitivement le rôle des rats et de leurs puces dans la propagation de la peste. On peut noter que M. Kesava Pai, avec lequel McKendrick allait écrire un article en 1911, et le directeur de l'Institut Pasteur de l'Inde à Kasauli, où McKendrick allait travailler entre 1905 et 1920, étaient membres de la commission.
Dans (Kermack et McKendrick, 1927), Kermack et McKendrick étudièrent un modèle mathématique avec trois compartiments: \(x(t)\) personnes saines, \(y(t)\) personnes infectées par la peste et \(z(t)\,\) personnes mortes ou immunisées. Les équations étaient \begin{equation}\tag{2} \frac{dx}{dt}=-k\, x \, y,\quad \frac{dy}{dt}=k\, x \, y - \ell \, y,\quad \frac{dz}{dt}=\ell\, y\; . \end{equation} \(k > 0\) est une sorte de taux de contact et \(\ell > 0\,\) une mortalité ou un taux de guérison. Les auteurs purent montrer que si les conditions initiales sont \(\,x(0)=x_0\), \(y(0)=y_0\) et \(z(0)=0\,\), \[\frac{dz}{dt}=\ell \Bigl ( x_0+y_0 - x_0\, e^{-k z/\ell} - z\Bigr ),\] une équation qui ne semble pas avoir de solution explicite. Ils supposèrent que l'expression sans dimension \(\,k\, z(t)/\ell\) reste relativement petite et utilisèrent l'approximation \(e^{-u}\simeq 1-u+u^2/2\) pour obtenir \[\frac{dz}{dt}\simeq \ell \Bigl [y_0 + \Bigl (\frac{k\, x_0}{\ell} - 1\Bigr )z - \frac{x_0\, k^2}{2\, \ell^2}\, z^2\Bigr ]\; .\] Cette équation de Riccati a une solution explicite \(z(t)\) qui donne un nombre de décès par unité de temps égal à (1), où \[A=\frac{\ell^3\, Q^2}{2 \, x_0\, k^2} ,\ B= \frac{Q\, \ell}{2},\ \tanh(\phi) = \frac{\frac{k\, x_0}{\ell} - 1}{Q}\; ,\ Q=\sqrt{\Bigl (\frac{k\, x_0}{\ell} -1 \Bigr )^2 + 2\, x_0\, y_0 \, \frac{k^2}{\ell^2}}\, . \] Noter avec (1) que \(A\) est le maximum de \(dz/dt\) (environ 900 par semaine dans la figure 1) et que \(t^*=\phi/B\,\) est l'instant où le maximum est atteint (19 semaines après le début dans la figure 1). Donc il n'y a réellement qu'un seul paramètre inconnu dans le processus d'ajustement, disons B, et Kermack et McKendrick ont probablement essayé plusieurs valeurs. Après une première estimation de B, ils se sont probablement rendus compte que leur ajustement à la courbe entière pouvait être amélioré en changeant légèrement les paramètres : A=890 par semaine et \(\,t^*=\phi/B=17\,\) semaines. Finalement, ils optèrent pour \(B=\mbox{0,2}\) par semaine et donc \(\phi=\mbox{3,4}\). Cependant le modèle a quatre paramètres : \(\,x_0\), \(y_0\), \(k\) et \(\ell\). Comment déduire quatre paramètres inconnus de seulement trois équations?
Avec \(R=k x_0/\ell\,\), on a \[A= \frac{\ell\, Q^2\, x_0}{2\, R^2},\quad B= \frac{Q\, \ell}{2},\quad \tanh(\phi)=\frac{R-1}{Q},\quad Q=\sqrt{(R-1)^2+2\, R\, y_0/x_0}\; .\] Donc \(Q=(R-1)/\tanh(\phi)\) et \begin{equation}\tag{3} x_0= \frac{2\, R\, y_0}{Q^2-(R-1)^2}=\frac{2\, R\, y_0}{(R-1)^2(\frac{1}{\tanh^2(\phi)}-1)}=\frac{2\, R\, y_0\, \sinh^2(\phi)}{(R-1)^2} \, . \end{equation} Mais les équations pour \(A\) et \(B\) indiquent aussi que \(\ell=2B/Q\) et \begin{equation}\tag{4} x_0=\frac{2R^2 A}{\ell Q^2}=\frac{R^2 A}{B Q}=\frac{R^2 A \tanh(\phi)}{B (R-1)}=\frac{R^2 A \sinh(\phi)}{B (R-1) \cosh(\phi)} \, . \end{equation} Avec les équations (3) et (4), on obtient \begin{equation}\tag{5} R(R-1)=\frac{2\, B\, y_0\, \sinh(\phi)\, \cosh(\phi)}{A} = \frac{B\, y_0\, \sinh(2\phi)}{A}\; . \end{equation} La seule racine positive de cette équation quadratique en R est \begin{equation}\tag{6} R = \frac{1+\sqrt{1+4 B\, y_0\, \sinh(2\phi)/A} }{2}\; . \end{equation}
Nous avons quatre inconnues mais trois équations. Plusieurs choix pour les paramètres \(\,(x_0,y_0,k,\ell)\) correspondent au même triplet \((A,B,\phi)\). On pourrait décider de fixer l'un des paramètres: la période infectieuse moyenne de la peste \(\,1/\ell\), la taille initiale \(x_0\) de la population saine à Bombay en 1905 ou le nombre initial de personnes infectées \(y_0\). Il ne semble pas possible de fixer k a priori.
On pourrait croire d'abord que le choix de la période infectieuse est relativement simple. D'après (Advisory Committee, 1907b, p. 765), la durée moyenne de la maladie dans les cas fatals est d'environ \(\,\mbox{5,5}\,\) jours. Cependant il y a aussi une période d'incubation d'environ 3 jours en moyenne (Advisory Committee, 1907b, p. 765). Enfin on ne devrait pas oublier que le modèle (2) est une simplification du processus d'infection. Les rats infectés infectent leurs puces, qui infectent d'autres rats et à l'occasion aussi des humains. L'épidémie de peste chez les humains est complètement déterminée par l'épizootie chez les rats, avec juste quelques jours de retard (Advisory Committee, 1907b, figure III).
Imaginons alors que le système (2) soit un modèle pour la peste chez les rats. Dans des expériences de laboratoire, les rats de Bombay auxquels la peste a été effectivement transmise mouraient en moyenne 9 jours après leur première exposition à des puces infectées (Advisory Committee, 1906a, p. 445). Mais encore une fois, on ne devrait pas oublier que cette durée peut ne pas avoir grand chose à voir avec la « période infectieuse apparente » puisque les puces quittent les rats seulement quand ils sont déjà morts. D'après (Advisory Committee, 1908, p. 285), des expériences ont montré que les puces peuvent rester infectieuses deux semaines pendant la saison de la peste mais seulement une semaine en dehors de cette saison. Il y a donc des variations saisonnières considerables, sur lesquelles on reviendra dans la section 4. Par conséquent, dans le cadre d'un modèle autonome aussi simple que (2), le choix de \(\,1/\ell\) n'est pas simple.
Considérons maintenant la taille initiale \(x_0\,\) de la population saine à Bombay en décembre 1905. à cette époque, la population de Bombay était presque entièrement concentrée sur « l' île de Bombay » et ses 22 miles carrés. Le recensement de février 1906 donna une population d'environ un million d'habitants (Advisory Committee, 1907b, p. 726). On choisit \(x_0=10^6\). L'équation (4) montre que \(R\) est solution de l'équation quadratique \[(A \tanh \phi) R^2 - (B x_0) R + B x_0=0.\] Numériquement, on obtient \(R\simeq 202\) et \(R\simeq \mbox{1,005}\). Mais (5) montre que \(y_0=AR(R-1)/(B\sinh(2\phi))\). Cela donne \(y_0\simeq \mbox{446 000}\) et \(y_0\simeq \mbox{0,06}\). les deux solutions sont absurdes, la première parce que l'épidémie de 1906 tua environ 10000 personnes, la deuxième parce que \(y_0\,\) est un nombre de personnes. Ainsi il n'est pas possible de prendre la population entière comme population à risque.
Il reste à vérifier si l'on obtient des valeurs réalistes pour les paramètres avec un choix de \(y_0\). Posons par exemple \(\,y_0=1\,\) au début de la courbe épidémique. En fait, (Kermack et McKendrick, 1927) (voir figure 1) ne précise pas à quel événement correspond l'instant \(\,t=0\). Une fois choisi \(y_0\,\), l'équation (6) donne \(R\). On peut calculer \(\,Q=(R-1)/\tanh(\phi)\) et \(\ell=2B/Q\). Finalement \(\,x_0\) est donné par (3) et \(k=R\, \ell/x_0\). Avec \(y_0=1\,\), on obtient \(\ell\simeq \mbox{4,32}\) par semaine, \(x_0\simeq \mbox{57 368}\) et \(k\simeq \mbox{0,0000823}\,\) par semaine. Noter que la période infectieuse moyenne serait de \(1/\ell\simeq \mbox{0,23}\) semaine, c'est-à-dire \(\mbox{1,6}\,\) jours. La population à risque serait \(\,N=x_0+y_0\simeq \mbox{57 369}\). La reproductivité serait \(\,R_0=kN/\ell\simeq \mbox{1,09}\) et numériquement presque égale à \(R\). Ce \(\,R_0\) semble assez petit en comparaison avec les valeurs typiques pour d'autres maladies infectieuses (Anderson et May, 1991 ; Keeling et Rohani, 2008, p. 21), en particulier vu que l'épidémie de peste n'est pas due à un lent accroissement de la densité de population jusqu'au seuil \(R_0=1\,\) mais presque sûrement à l'arrivée par b\^ateau de rats infectés. La troisième pandémie de peste a commencé en 1894 à Hong Kong. Cependant, comme la « période infectieuse apparente » \(1/\ell\) (dont l'interpretation est difficile, comme on l'a vu ci-dessus) est aussi très courte, le temps de doublement \(\log(2)/(kx_0-\ell)\,\) au début de l'épidémie prend une valeur raisonnable, environ 13 jours. Un problème plus grand survient quand on considère la population à risque \(\,N\simeq \mbox{57 000}\). Avec les rapports sur la distribution géographique des cas de peste chez les humains (Advisory Committee, 1907b, carte I, p. 727 et p. 787-794), il semblerait que toutes les zones densément peuplées de l'île de Bombay furent touchées par l'épidémie. Il n'y a pas de raison évidente pour que seules 57000 personnes soient à risque lorsque la population totale est d'environ un million.
On pourrait se demander si un choix légèrement différent de \(y_0\,\) (supposé être un entier) pourrait conduire à des valeurs de paramètres plus raisonnables. C'est ce que montre le tableau 1, où l'on inclut \(\,R_0\) plutôt que \(k\). Les courbes épidémiques correspondantes (non représentées) restent toutes proches de celle de la figure 1, mais l'approximation se détériore à mesure que \(y_0\) augmente.
| \(y_0\) | \(x_0\) | \(1/\ell\) (jours) | \(R_0\) |
| 1 | \(57\,368\) | \(\mbox{1,6}\) | \(\mbox{1,09}\) |
| 2 | \(35\,439\) | \(\mbox{3,0}\) | \(\mbox{1,17}\) |
| 3 | \(28\,202\) | \(\mbox{4,3}\) | \(\mbox{1,24}\) |
| \(b(P)\) | fertilité des rats \(b(P)=r\, P/(1+P/K)\) | \(r=\mbox{0,4}\)/mois | (Leslie, 1945) |
| \(K=\mbox{50 000}\) | ajustement | ||
| \(1/m\) | espérance de vie des rats | \(m=\mbox{0,03}\)/mois | (Leslie, 1945) |
| \(1/c\) | temps pour que les puces libres trouvent un hôte | \(c=30\)/mois | Advisory Committee, 1907a, p. 475 |
| \(\omega\) | proportion des puces libres qui trouvent un hôte humain | \(\omega=2\%\) | ajustement |
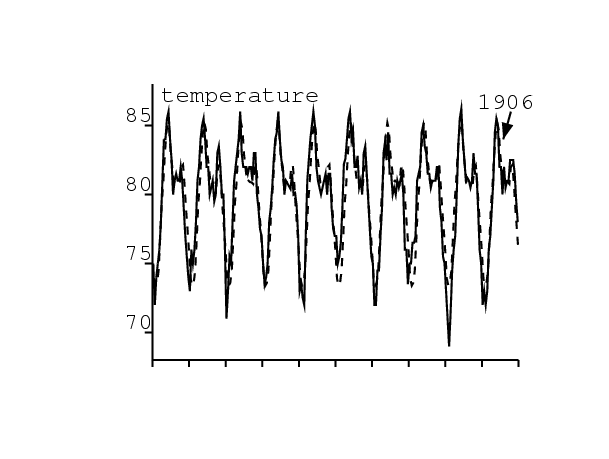
| \(\pi(\theta)\) | probabilité de transmission du puce au rat ou à l'homme (θ en ° F) | \(\pi(\theta)=\pi_0 \times (\mbox{0,75}-\mbox{0,25}\tanh(\theta-80))\) | Advisory Committee, 1908, p. 283 |
| \(\pi_0=90\%\) | ajustement | ||
| \(\theta(t)\) | température (° F) | figure 3 | Advisory Committee, 1908, figure I |
| \(1/m'\) | durée de la peste chez les rats | \(m'=3\)/mois | Advisory Committee, 1906a, p. 445 |
| \(\varepsilon\) | proportion de rats guérissant sans immunité | \(\varepsilon=10\%\) | Advisory Committee, 1908, p. 284 |
| \(\varepsilon'\) | proportion de rats guérissant immunisés | \(\varepsilon'=10\%\) | Advisory Committee, 1908, p. 284 |
| \(f\) | nombre moyen de puces par rat | \(f=4\) | Advisory Committee, 1907b, p. 752 |
| \(\pi'\) | probabilité de transmission du rat à la puce | \(\pi'=\pi_0\) | hypothèse |
| \(1/a\) | durée de la peste chez les humains | \(a=4\)/mois | Advisory Committee, 1906b, p. 526 |
| \(\sigma\) | mortalité | \(\sigma=90\%\) | Advisory Committee, 1907b, p. 762 |